代号为 COVID-19 的新型冠状病毒肺炎在全球肆虐着,剧情翻转的非常快,目前欧美已经成为了全球的重灾区。 本文介绍如何使用 Elastic Stack,实现对国内外疫情发展态势的分析。介绍一种简单易行的数据分析流程。说不定你也可以得出独到的高价值洞察。
本文使用的 Elastic Stack 版本和环境如下:
- Vagrant 的基础镜像 bento/centos-8
- Elasticsearch 7.6.1
- Kibana 7.6.1
- Logstash 7.6.1
关于使用 Vagrant 环境搭建 Elastic Stack 的方法,见我之前的文章。本文的数据分析处理流程图如下所示。
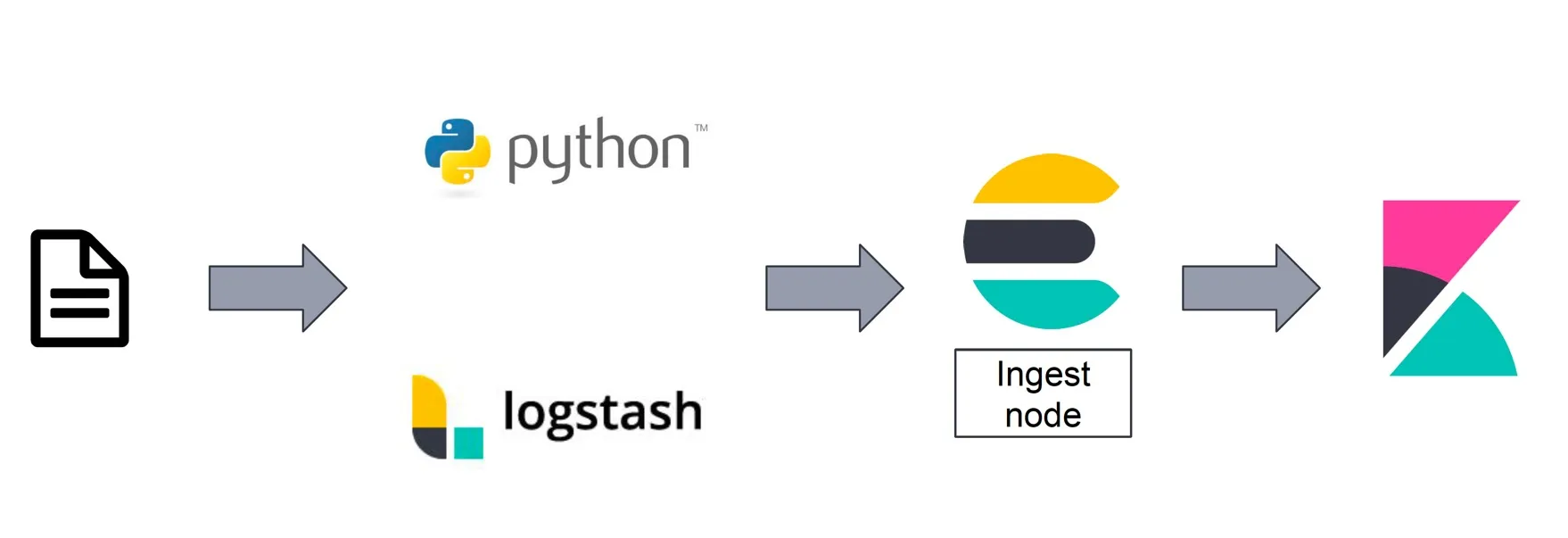
分析和展示丁香园数据
本文的目标分析数据源是 https://ncov.dxy.cn/ncovh5/view/pneumonia 这个也是我们最近一直在关注的关于中国的疫情公布平台。
丁香园网页的数据被香港大学的 Isaac Lin 同学,通过他所开发的网络爬虫抓取加工后,用 API 的形式和 csv 数据文件的形式提供了出来,他的爬虫程序和结果数据给很多目前分析疫情的人带来了很大的帮助,有不少人去他的 blog 和 github 上点赞和评论的。
你可以用 Python 程序调用 Lin 同学的 API 然后在将处理后的结果写入 ES,这样的脚本可以参考 Rockybean 的这个 https://www.yuque.com/elastictalk/blog/et25?from=timeline。也可以用下面的命令将Github 的 csv 文件下载到本地,在做手工的数据分析,这样也等于是对林同学的数据内容和定义进行一次深入的探索,这也将更有益于你理解数据,方面后面使用 Kibana 做数据分析。
在本机使用 git 做数据下载和同步的命令如下。
| |
你也可以用用git pull命令在日后做数据更新,并进行后续的跟踪分析。
同步到本地的数据也可以使用 Logstash 或者是 Filebeat 持续的同步到 ES 中,这样就可以在 Kibana 上看到每日的实时更新结果。
导入数据并初始化索引
本文选择了最简单直接的方式,使用 Kibana 自带的数据导入功能,手工导入丁香园的 csv 时序数据文件 csv/DXYArea.csv。 如下图所示。
这个工具是机器学习的周边工具 数据可视化器 ,它对这份数据做了初步的分析和识别,点击导入,然后在下面点击 Advancd ,进入高级设置,如下图所示:
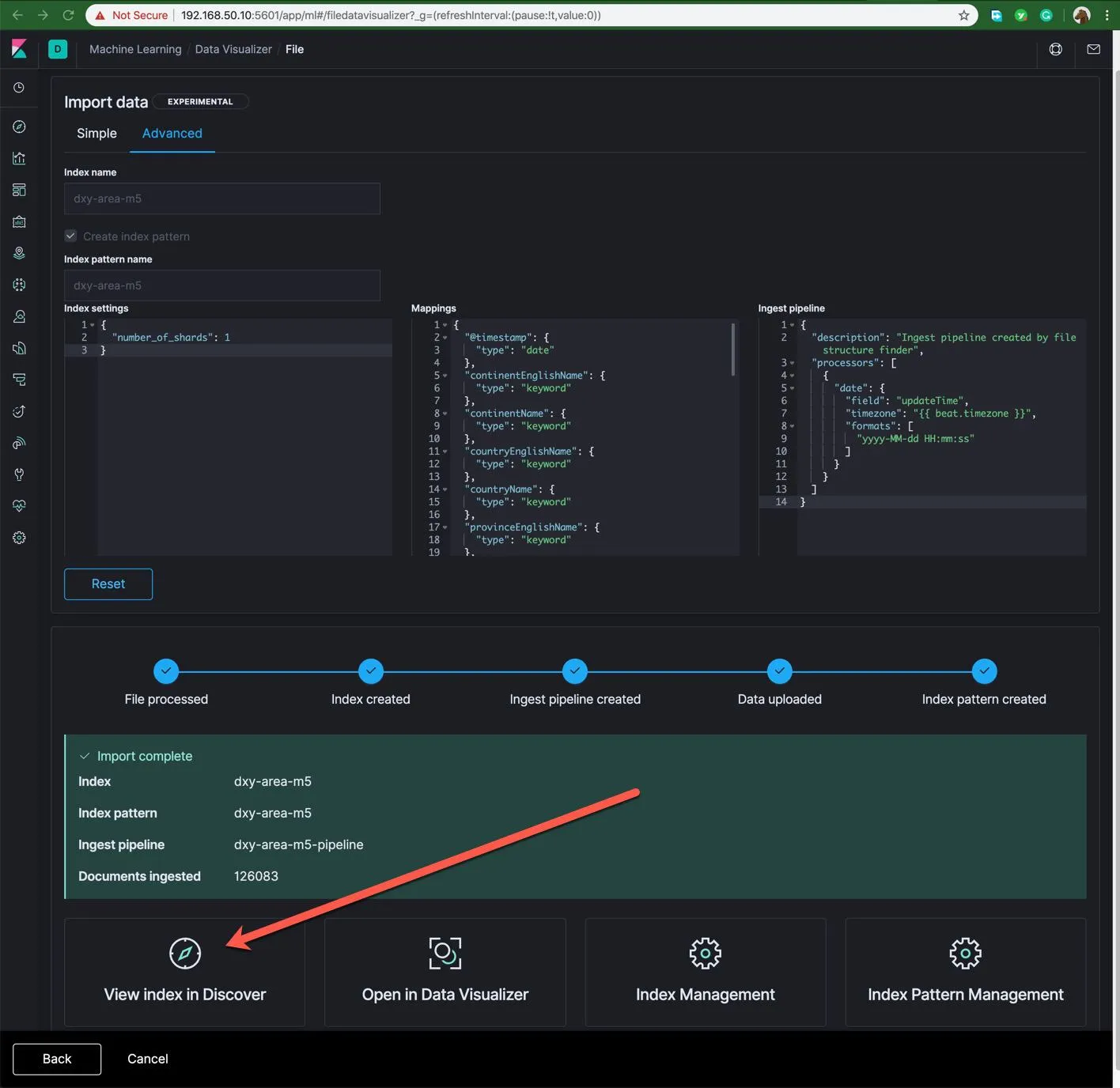
- 可以在 index name 中可以输入
dxy-area-m5作为本次新建的索引名称。 - 然后删除默认的 Mapping 定义,输入下面的重新重定义的数据结构。
| |
对以上 Mapping 的简要说明:
- 增加了字段 level, is_china 和 Location,你也可以加入你所需要的其它待用字段,所有新增无值字段都需要后期进行初始化。
- level 定义了数据记录的级别为:国家、港澳台和省级。
- is_china 定义了国内外数据标识
- 在导入后,本文使用的字段的批量初始化/维护是调用 /_update_by_query 方法,也可以是使用 ingest pipline 的方式,或者其它 Elastic Stack 中的其它替代功能。
如上图所示的数据导入成功之后,点击 View index in Discovery, 我们可以使用 Kibana 的 Discovery 功能来对所导入的数据进行分析和确认,特别是一些关键字段的数值。观察这些数据的格式和内容的含义是什么。使用 filter 功能了解数据的内容和特征。建议使用下面的 filter 和组合探索一下【也可以使用 kql 语言做查询,如果用 kql 做查询的话,也可以很方便的将这些查询条件进行复用】。
- countryName:中国
- NOT countryName:中国
- countryName:中国 / provinceName:中国
- countryName:中国 / NOT provinceName:中国 / cityName exists
- countryName:中国 / NOT provinceName:中国 / NOT cityName exists
- countryName:中国 / cityName: 境外输入
以上的 / 是多个 filter 叠加的含义,可以大概的猜测出下面的结论。
- 中国国内数据
- 国外数据
- 中国省级统计数据
- 中国各省的各个城市的统计数据
- 中国的港澳台数据
- 中国海关所监控到的境外输入数据
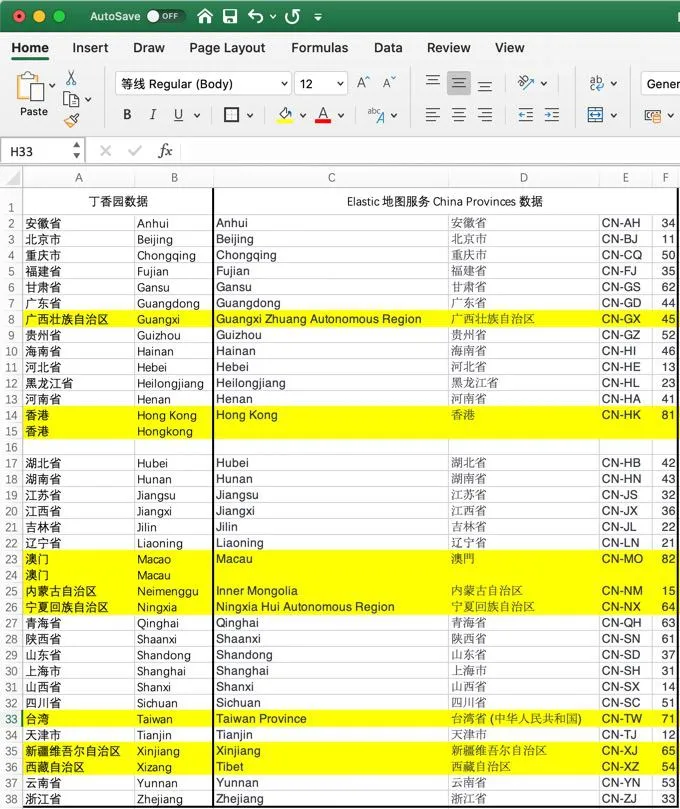
为了后面使用省的名称做地图分析,这里需要查看数据中各个省英文名称,以广西为例,设置查询条件:provinceEnglishName Guangxi
现在来浏览 Elastic Map 地图服务所引用的中国各省的中英文名称和代码,查看 https://maps.elastic.co/#file/china_provinces ;
可以发现现所导入的数据和 Elastic 地图服务的官方数据不一致。
下图是用 Excel 分析对比的结果,建议使用 Python、logstash 或者其它工具在导入的过程中对这个字段做预处理和校准。
本文下面描述了 Dev Tool 中运行相关的数据优化和及校准脚本。
| |
注意:以上的三个 POST 方法调用的对象是 dxy-area-m5 ,这个索引的名字需要和你上面导入数据创建的索引一致。由于是手工初次处理这些数据,建议再次运行以上的一系列搜索过滤条件,确认这些目标字段和数据得到了正确的处理。
可视化和展示数据
在分析数据就绪了以后,下面介绍一组通过 Kibana 进行数据可视化分析展示的思路和方法。
💻 从 Discovery 界面中直接调用可视化视图创建
在 Discovery 的查询界面里,点击左侧 fields 清单中的 provinceName,或者其它想进行可视化分析的字段,点击后即可查看其中一部分的数值分布情况,点击下面的 Visualize 按钮。就可以进入可视化编辑模式。
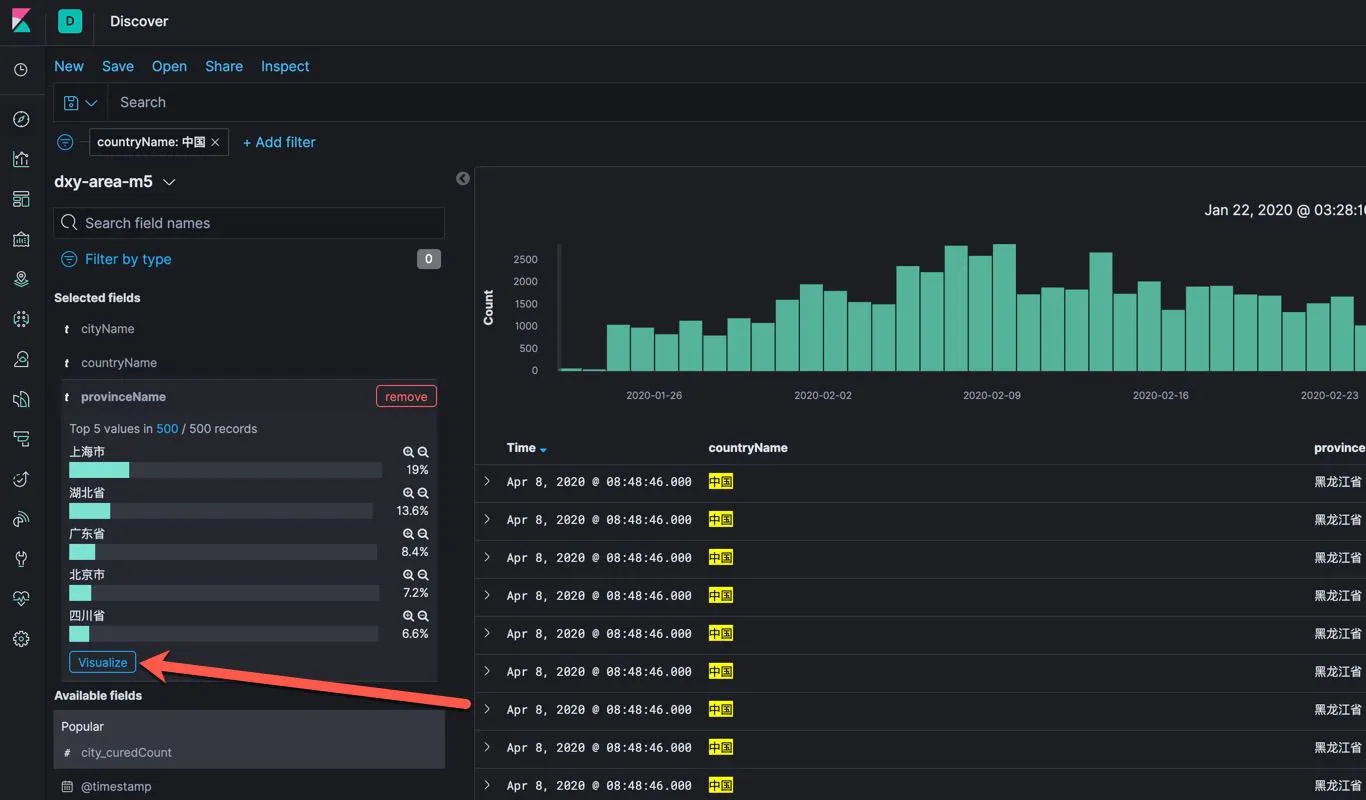
进入这个 field 的默认可视化配置模式,选择 Y 轴的指标为 province_confirmedCount 的最大值,然后在上方增加 is_china:true 和 level:province 过滤条件后,就可以得到下面的结果。
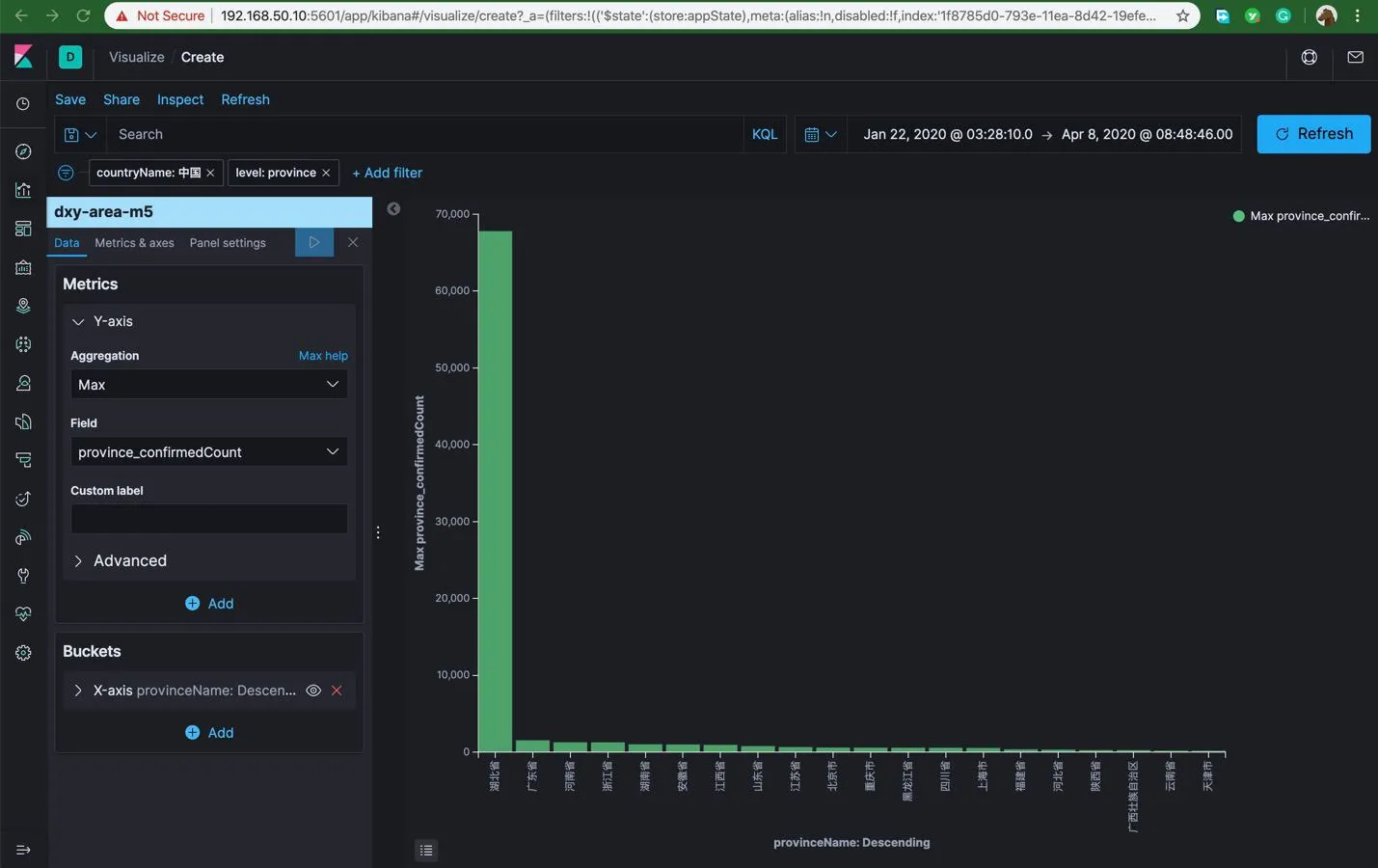
还可以对 Buckets 里面 X 轴的值进行调整,使用省的名字。 这样基本上得出了确诊数省排名的结果。或者你还可以调整出其它的分析结论。在分析结束后,点击左上角的 Save ,将分析组合保存下来用于后期的仪表板的制作。
💻 使用 Visualization 的 lens 功能探索数据
点击 New Visualization,选择左上角的 Lens 图标。在 CHANGE INDEX PATTERN 中选择目标的索引如:dxy-area-m5。 拖拽几个字段进入中间的显示区:continentName countryName province_confirmedCount 这些字段,也可以尝试将这些字段拖入右侧的 X 轴或者 Y 轴。
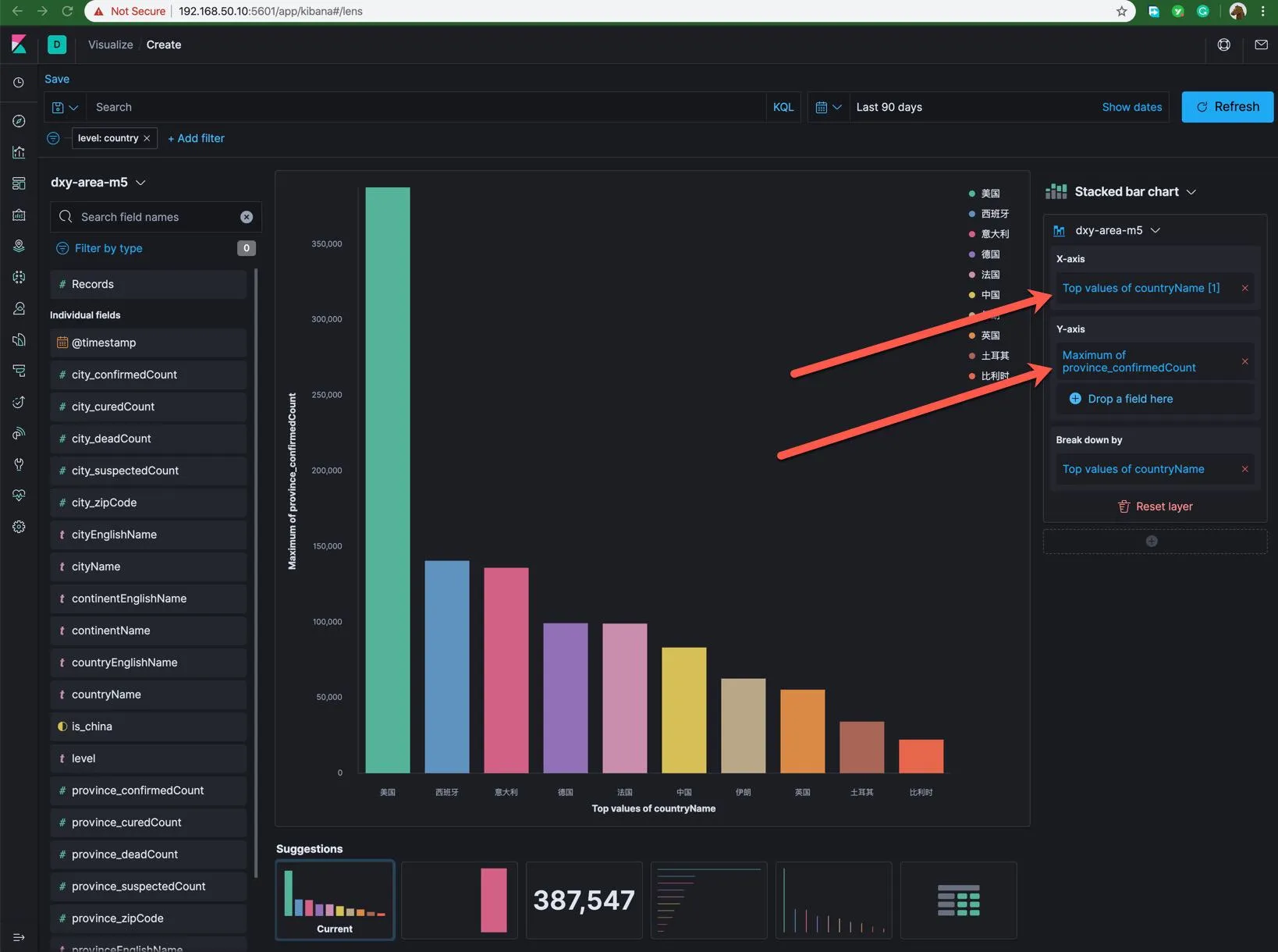
拖入不同的位置,图形下方的建议可视化展示风格会随之变化,Lens 功能在预判和猜测你可能会用到的展示和分析组合。感受这些建议图形所提供的数据分析的线索。
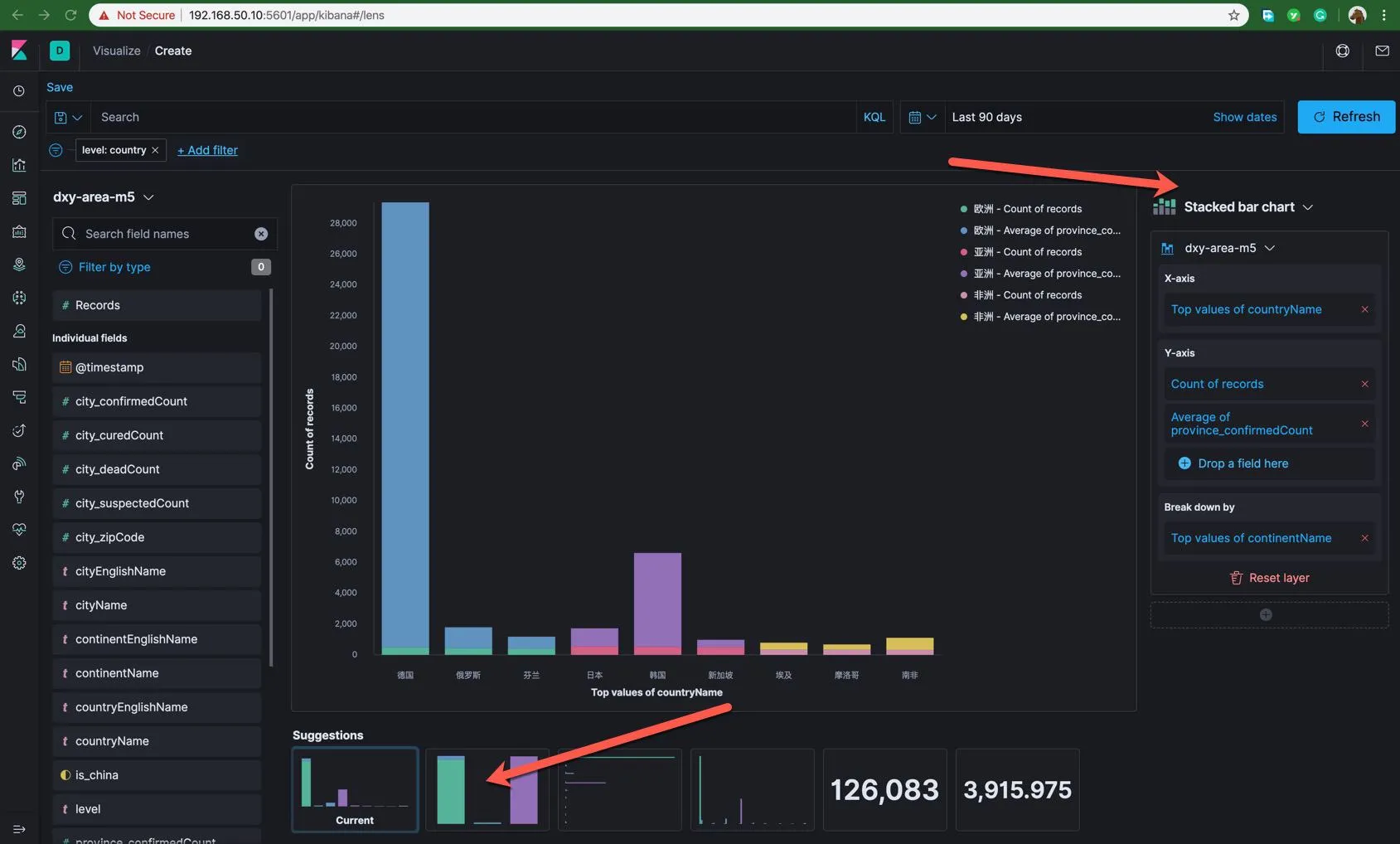
同样的,你也可以在上面使用过滤器和时间段选择功能,这些数据筛选条件发生变化之后,可视化的图形数据也会随之变化。
使用 TSVB 时序数据可视化构造器
这个控件的功能稍微复杂一些,用下图说明它的用法。
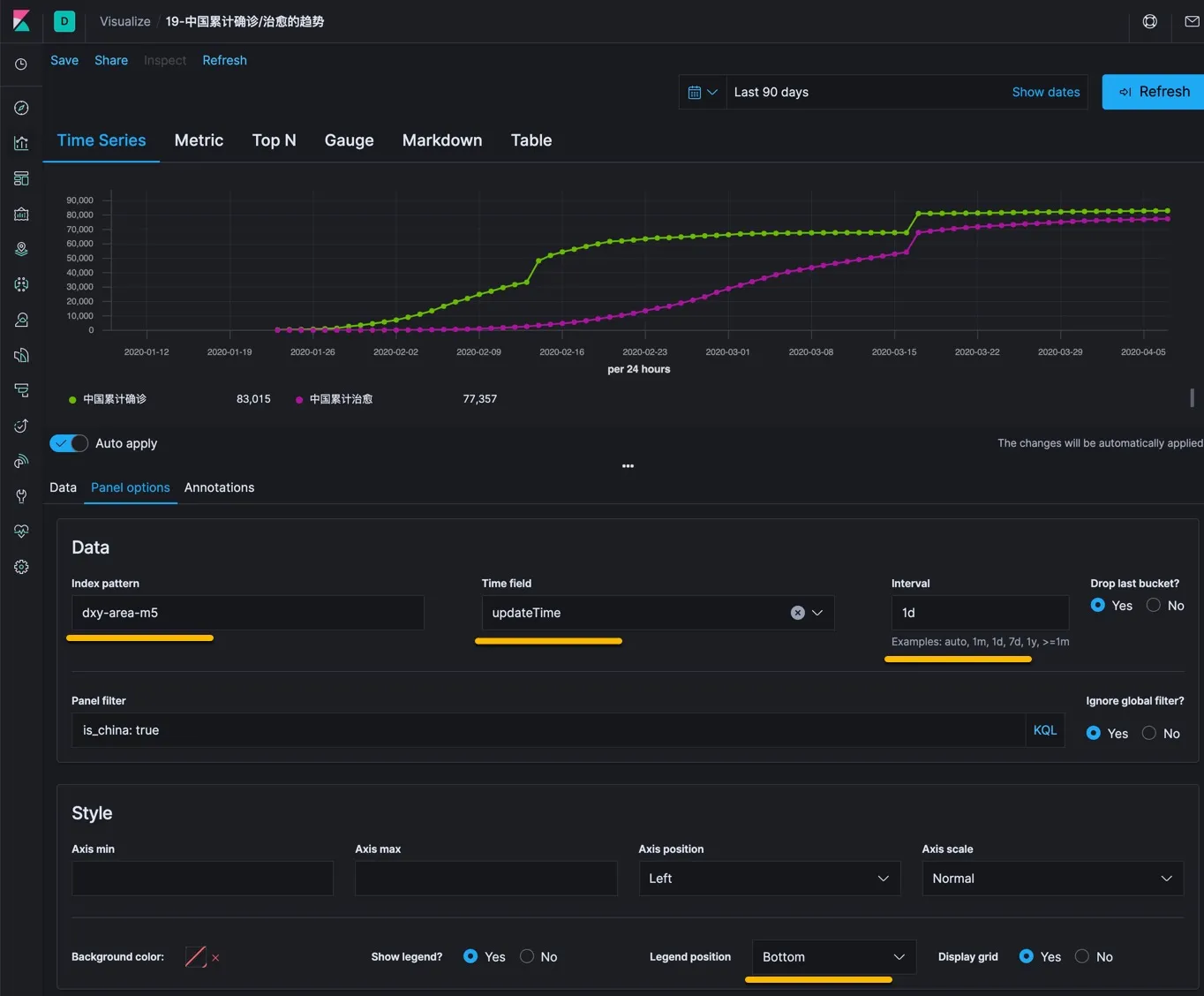
如上图所示,现在 Panel Options 里面设置需要使用的数据索引,以及其他参数。
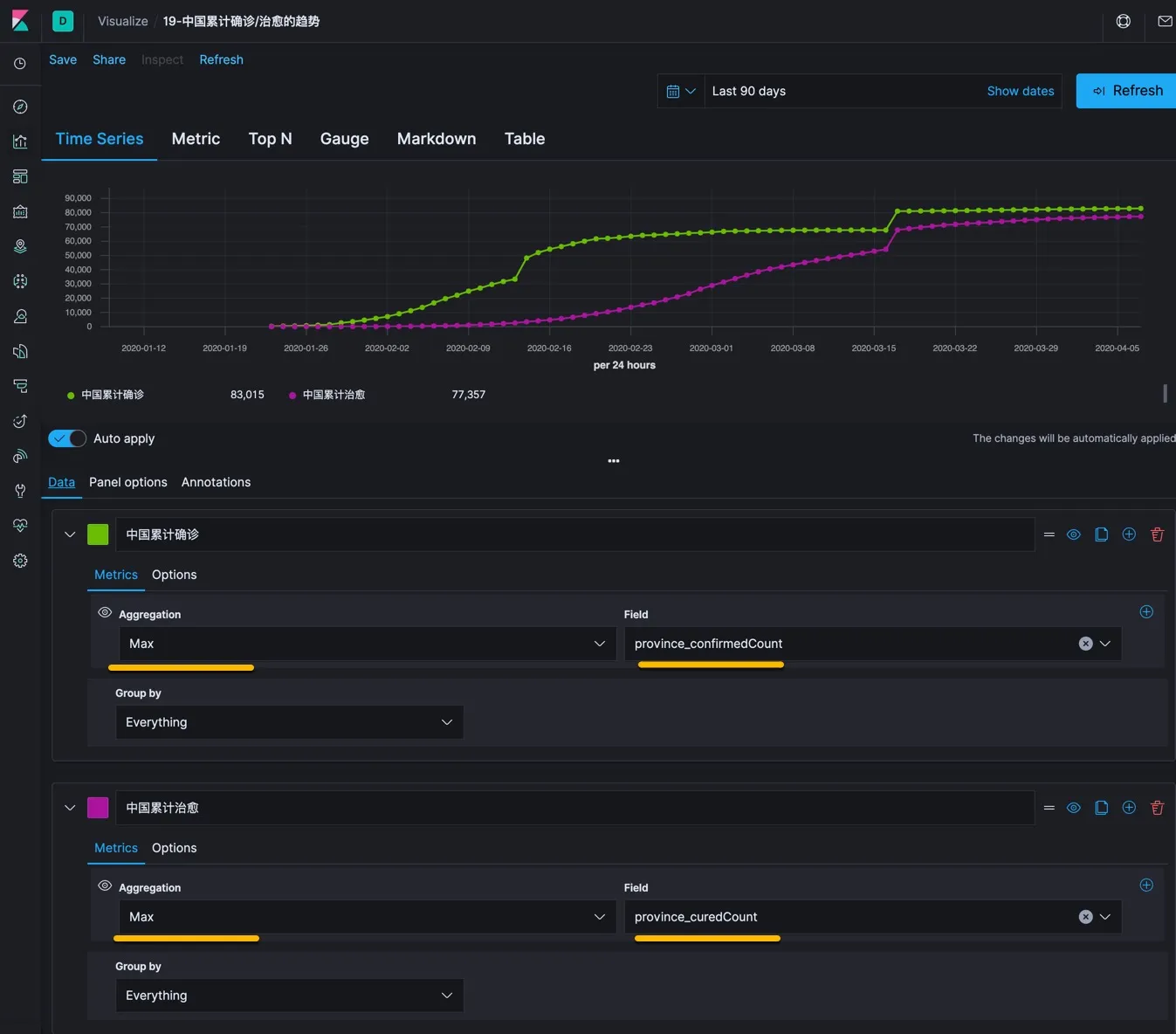
然后在 Data 中选择需要显示的数据指标,如上图中选择了全国累计确诊和累计治愈,两个指标。将他们放在一起更能回答这样一个问题:是否治愈的速度是足够的,如果治愈速度跟得上的话,说明医疗资源是足够用的,如果这两条线之间的落差比较大就危险了。
上方的 TSVB 图形显示了所有数值和格式调整后的预览效果。可以无限的修订知道满意为止。这个控件天然支持指标数值、排行榜、速度表、Markdown 文本和数据表。可以切换到不同的视角看它的展示效果。
使用地图展示省级累计数据
我们可以使用已经导入的数据在地图上显示省级的累计确诊和治愈人数。过程是这样的:
- 点击 Kibana 左侧的 Maps 图标,创建一个新的地图。
- 创建图层,选择 EMS Boundaries ,选择这个图层所使用的基础地图为 China Provinces
- 点击 Add layer 按钮
- 在图层配置里输入图层名称缩放级别,透明度的设置
- 设置 Tooltip fields 的设置中增加 name(zh) ,中文的省名称
- 设置 Term Joins 的规则,点击 Join 关键字,设置索引中的数据和地图的关联。如下图所示,这就是我们为什么要把导入数据中的省英文名称与 EMS 的定义数据对齐了。
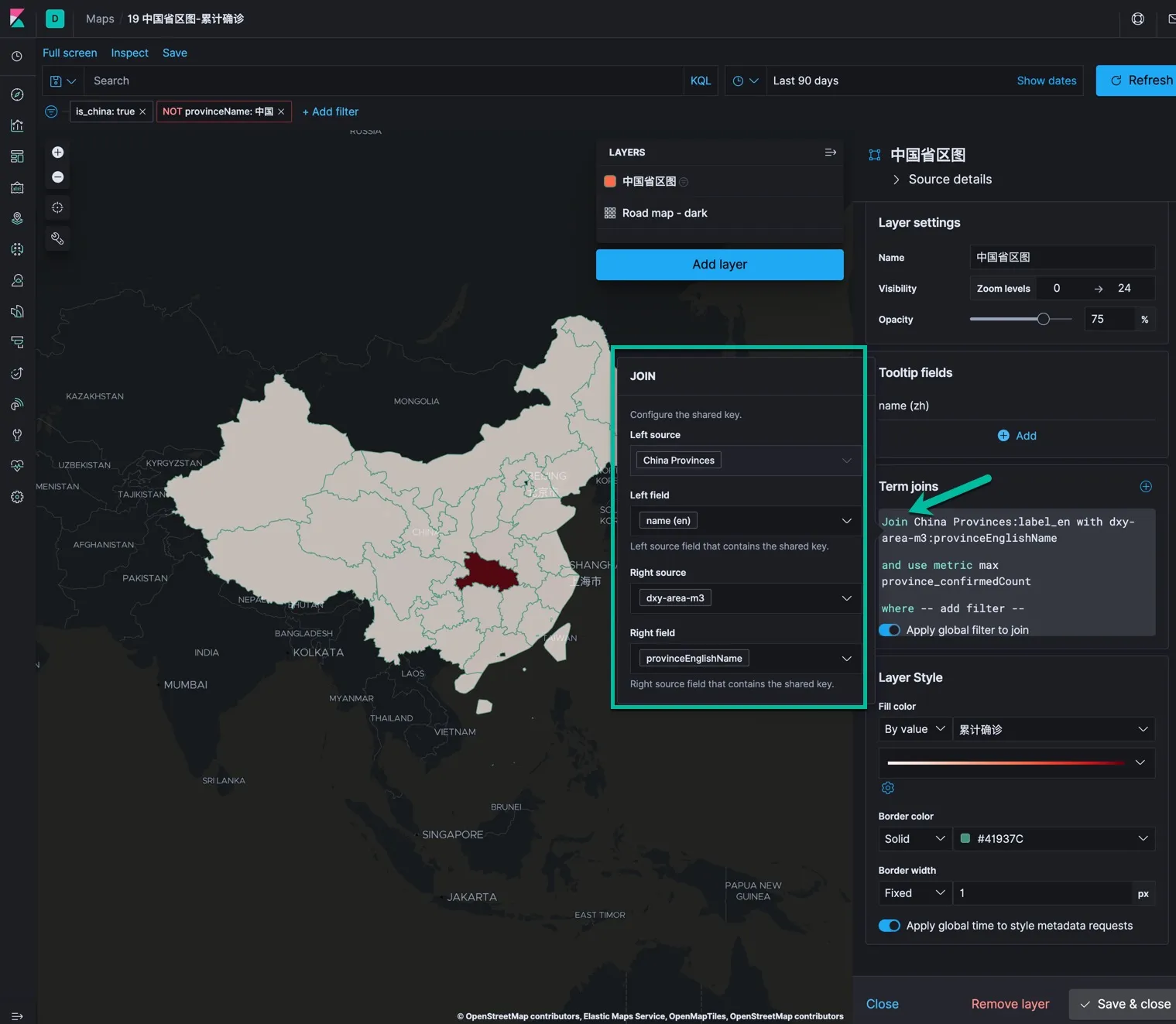
- 点击 and use metrics 设置在每个省上显示的数据。如下图所示。
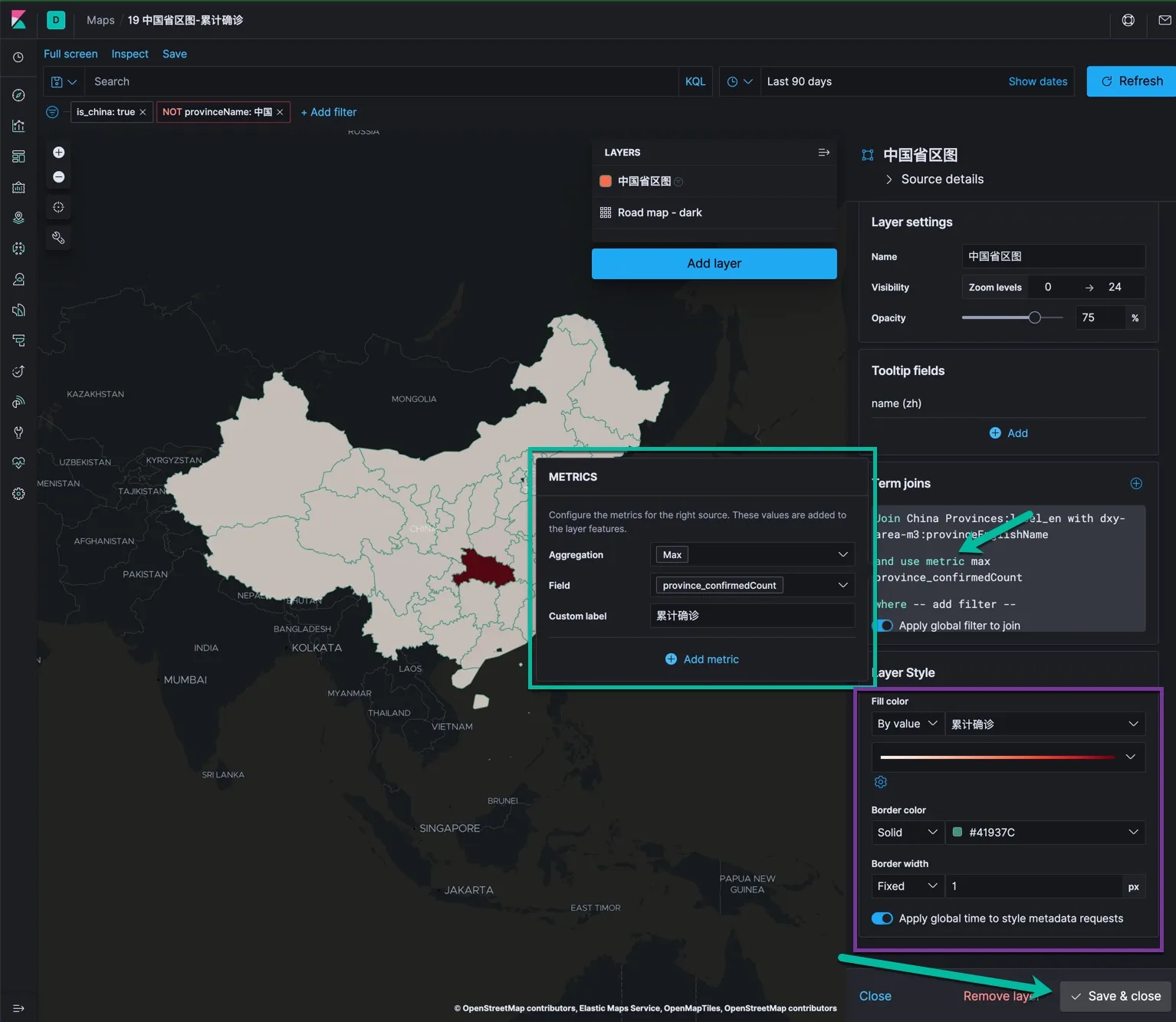
- 最后设置 Layer Style, 将 Fill color 填色设置为 By Value, 选择省累计确诊,下面的颜色可以选择白色到深红的过度。
- 最后点击 Save & close 按钮。
这里的技术点在于:Elastic 地图中的基础数据(地理名称代码)必须和目标索引中的相关字段能够匹配上(join)上,然后才能将索引中的实际做聚合运算的字段根据地理名称进行处理,例如根据数值的大小,将各个省填充成不同的颜色,用 tooltips 显示这个省的数据信息。
创建 Dashboard 仪表板
上面所设计的所有的图示和地图都是创建 Dashboard 的素材,等做了一些素材之后就可以做仪表板了。这个过程就是在空白的仪表板上逐渐加入合适的图表,然后不断调整图表布局的过程,然后呈现出一个阶段性的效果。如下图所示。
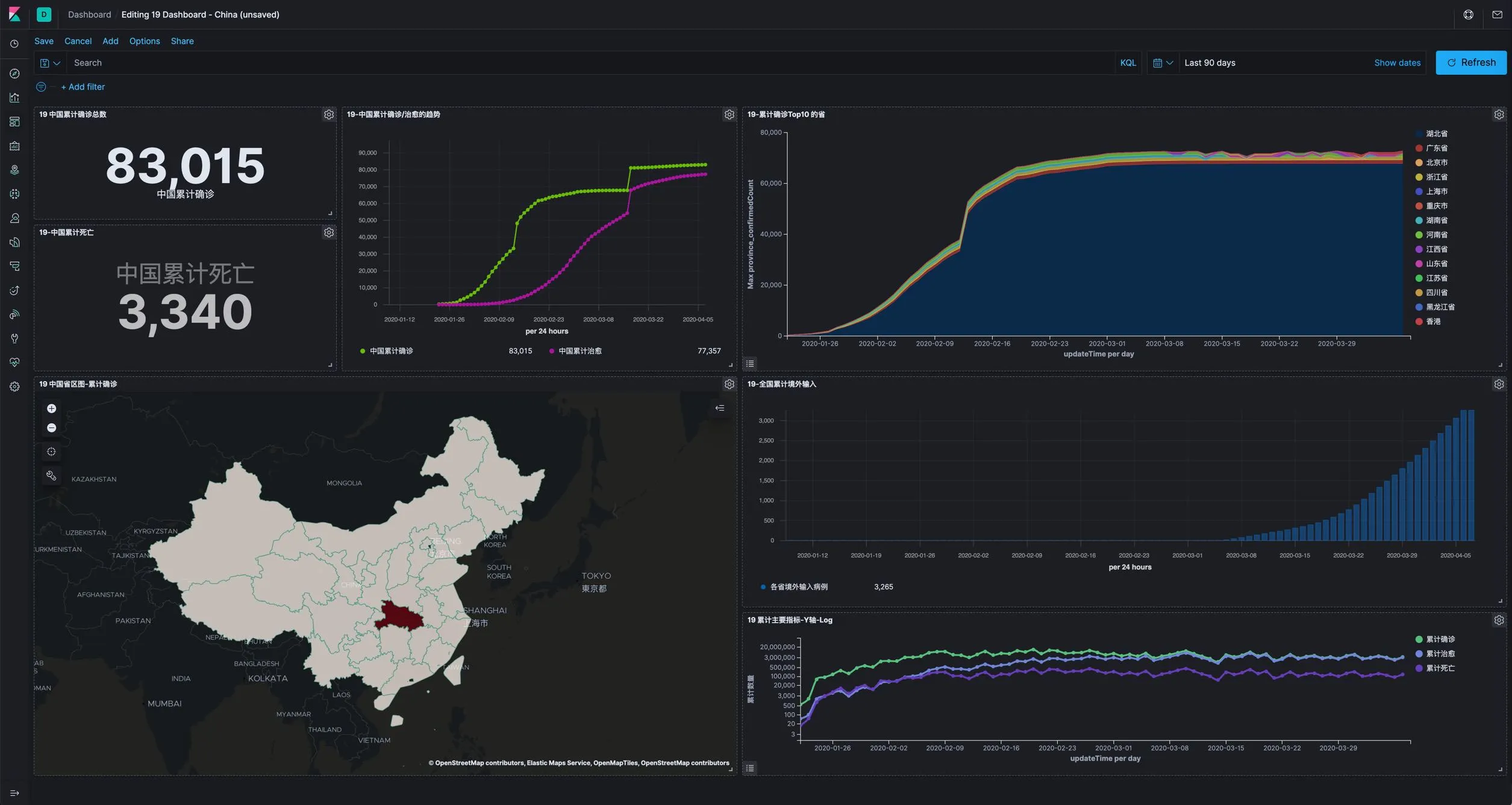
世卫组织数据的处理和展示
浏览世卫组织的数据 https://github.com/CSSEGISandData/COVID-19
基于以上数据可以制作一个如下的仪表板:
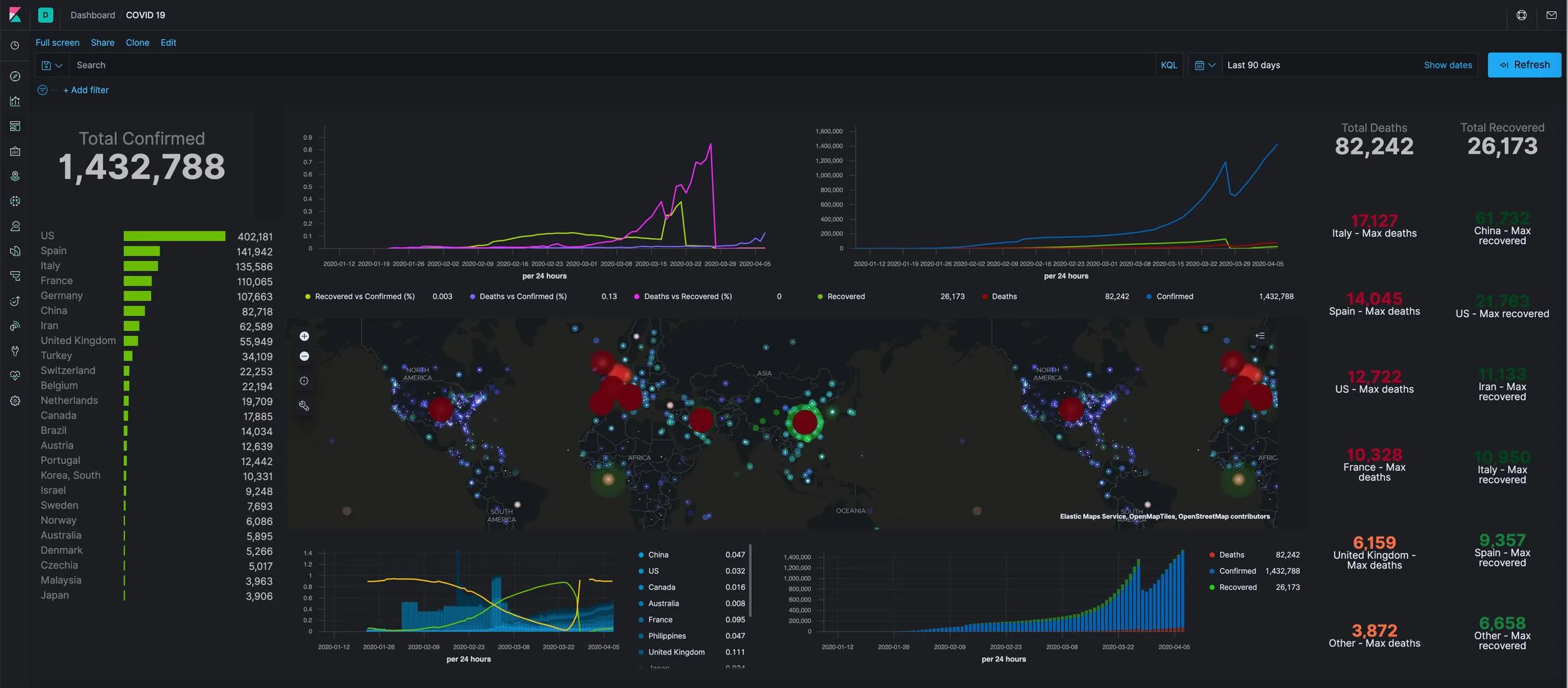
这个仪表板中的地图是亮点,建议仔细学习研究一下。 这个仪表板的来源是一篇国外的文章: https://www.siscale.com/importing-covid-19-data-into-elasticsearch/
我在一个小时左右,根据经验顺利的在我的实验环境里顺利生成了这个成果。下面是根据这篇文章怎么样使用 logstash 导入 Github 中世卫组织发布的数据,并持续与之保持同步。这里是他们的代码:https://github.com/siscale/covid-19-elk
下面描述如何使用这份代码。首先你需要有一个安装好的切正常运行的 Elasticsearch 7.6.1 服务器,一个可以正常使用的 Kibana 7.6.1 服务器。在此基础之上,安装 logstash 服务器,修改并放好 logstash 的配置文件。 在 Kibana 的 Dev Tool 中导入索引的 Mapping。启动 logstash 服务器,等待和确认数据的传入。导入 Kibana 的相关对象。浏览查看和确认 siscale (国外一家 Elastic 的合作伙伴公司) 的作品。理解每个可视化展示控件的设计细节。
你可以参考下面的安装步骤和注意事项。
- 登录 Kibana,进入 Dev Tool 中,将文件 index-template-mapping.json 中的内容复制进去并点击执行按钮。
- 安装 Logstash 7.6.1
| |
- 将配置文件中的 /etc/logstash/covid-19-hashes.json 修改为 /usr/share/logstash/covid-19-hashes.json 然后把它们复制到 logstash 的配置目录中
| |
- 确保你的虚拟机(测试环境和 github 以及其他的国外基本正常的情况下)网络正常的情况下,启动 logstash 服务并且关注该服务的日志信息
| |
PS:在日志中可以看到 logstash 完全正常的启动成功,或者看到报错,这时候就需要停止 logstash 服务,并进行调整。直到服务彻底运行成功不报错。
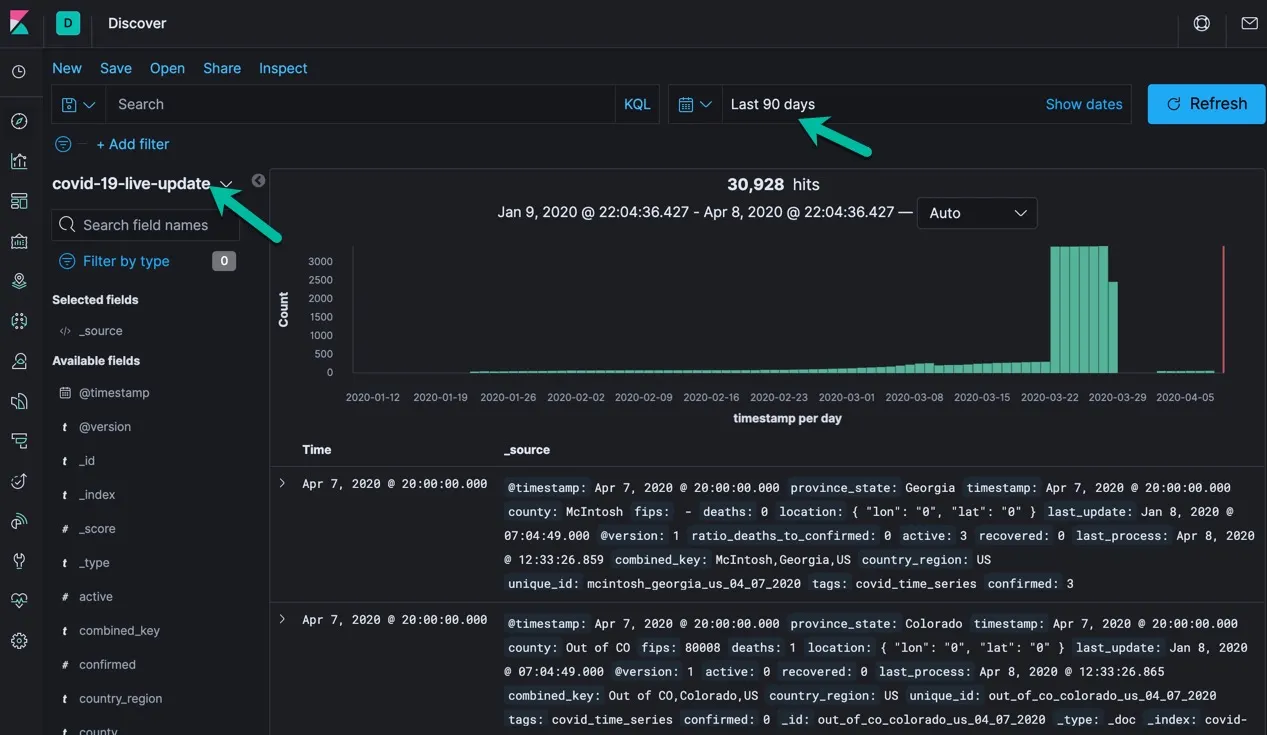
在 logstash 服务正常运行的情况下,世卫组织的数据是会被正常的导入到 ES 中的,你可以在 Discovery 中查看如下的查询结果。那么恭喜你,你已经和世卫组织的数据保持实时同步了。
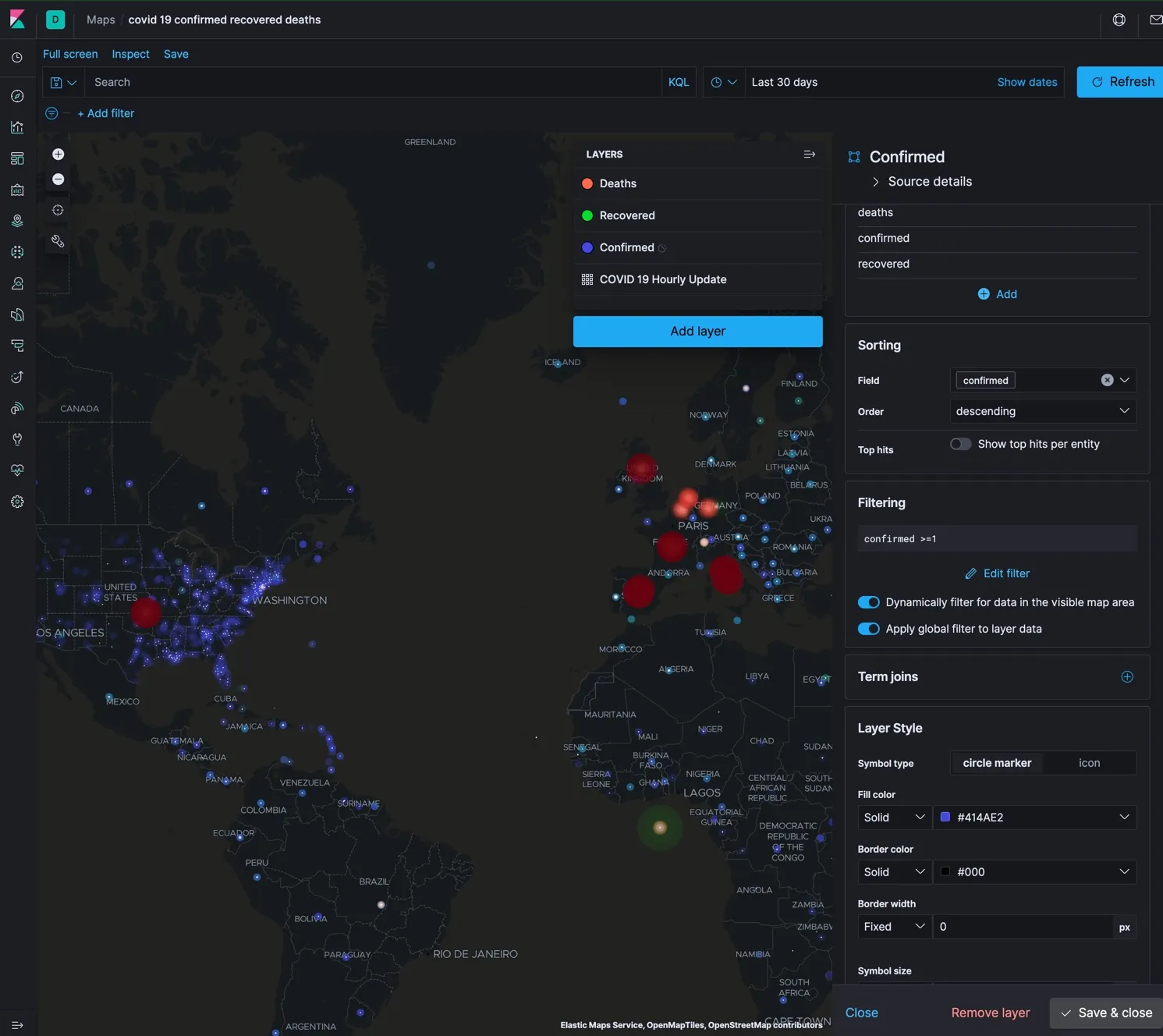
最后是导入该项目的仪表板对象。操作步骤参考:登录 kibana, 进入管理, 点击 Kibana 下面的 saved objeces ; 点击 import 按钮。选择 kibana-7.6.1-covid-19-dashboard.ndjson ,然后即可浏览名为 COVID 19 的仪表板了。导入后在 Kibana 的仪表板清单中选择查看名为 “COCID 19” 的仪表板。预祝你能看到和我相同的结果,建议仔细查看他们的地图设计,做的是非常的细致,如下图所示,它是三个图层叠加的显示效果。
总结
最后希望你通过本文已经成功的展示出了以上的预期结果。下面简单总结一下相关知识点。
- 对陌生数据集的首次探索可以是手动导入 csv 文件的手动过程
- 在导入的过程中需要做适当的 field mapping 的调整,和扩展,让后期的查询和数据分析更加清晰
- 对导入后的数据,充分利用 Discovery 的查询和分析能力,确定好数据校准和调优的更新策略
- 充分利用 ES 的批量查询修改 API,可以轻松快捷的实现数据修订。
- 地图的使用重点在地理信息代码和数据索引中的实际 field 的 join,因此需要特别设计和维护 join 的字段,确保他们的精确性。
- 仪表板的制作和设计依赖于各种图标的设计
Elastic Stack 在本案例中得到了充分而综合的运用。从 E 到 L 到 K 一个都不能少。建议大家能平衡掌握这个技术栈的各种技术能力,补足不太擅长的部分。
本文参考的网址如下:
- https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6
- http://covid.surge.sh/
- https://informationisbeautiful.net/visualizations/covid-19-coronavirus-infographic-datapack/
- https://ncov.dxy.cn/ncovh5/view/pneumonia
- https://github.com/CSSEGISandData/COVID-19
- https://lab.isaaclin.cn/nCoV/
- https://github.com/siscale/covid-19-elk
- https://www.mapbox.cn/coronavirusmap/#3.35/28.47/109.74
- https://ncov.deepeye.tech/
- https://www.siscale.com/importing-covid-19-data-into-elasticsearch/