
最近 Qwen3 Coder 30B 模型在春节期间很火,之前 Claude Code 体验不错,但是总想避免多开一个 AI 订阅;所以一直想用在本地运行编程大模型来搭配 Claude Code。
选取我内存最大的 MacOS 机器,来安装测试这个组合。安装前,觉得 MacBook Pro M1 Max 64GB 内存的配置应该差不多,结果速度其实差很多。不知道是不是我的配置不对,还是哪里有性能问题,或者是什么原因导致的。
作为一次踩坑记录,也有必要记录以下;或许通过这个梳理可以找出问题所在。
用 Ollama 在本地运行 Qwen 模型
首先是安装 Ollama 和 Qwen3 Coder 30B 模型,安装过程很顺利, 相关命令如下:
| |
这样Qwen 模型就在本地跑起来了,而且使用了一个独立的控制台窗口来显示日志,同时它可以服务与本地的多个 Cloud Code 客户端实例。 根据ChatGPT的建议,使用了 64k 的上下文长度来提升性能。
还可以使用下面的命令,在另外一个终端窗口中来测试模型是否正常工作:
| |
接下来是安装和配置 Claude Code,安装过程也很顺利,相关命令如下:
| |
当然在运行 Claude Code 命令行工具前,还是需要先配置一下 Claude Code 的 settings.json 文件,将我的目标代码库中可忽略的大目录添加到 ignored_directories 中,来提升性能。
根据 Claude Code 的官方文档,它与 Ollama 的集成感觉是非常简单,其实也确实是非常简单的,相关命令如下:
| |
用这条命令启动 Claude Code后, Ollama 的日志窗口就会显示出对模型的调用了,使用以上命令参数可以让输出干净很多。当 Claude Code 开始运行 /init 命令后,它就开始读去文件了,这时候 GPU 也基本上被占满了,ollama 对 GPU 的使用率是 80+%。然后就可以听到风扇开始呼呼的转了。
经过10多分钟的等待,Claude Code 读取文件的总和没有超过 10个,显示消耗了 300多个 tokens。
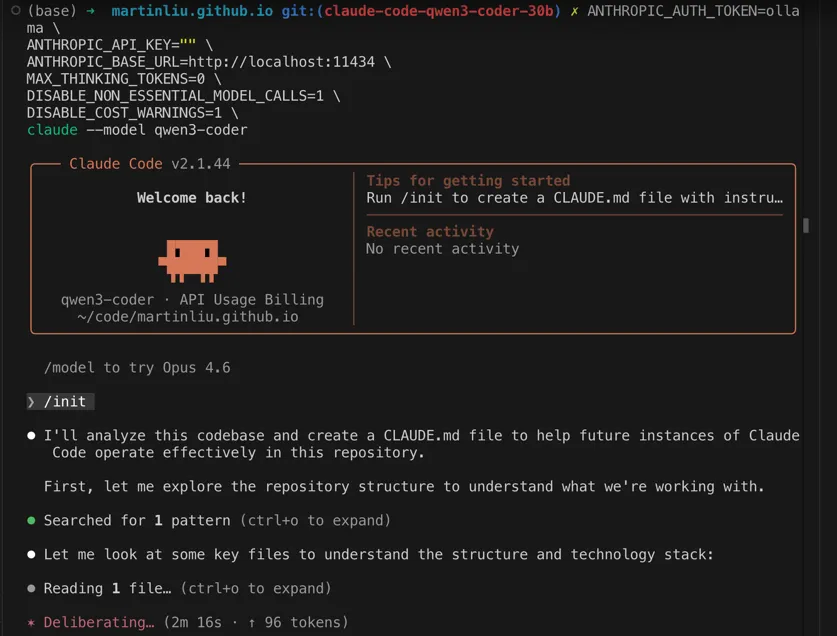
然后就是进入漫长的等待,等了大概20分钟,观察 ‘init’ 命令的输出,可以确定,这个进度是无法正常使用这个组合的。在后台看下模型对 GPU 的使用率:
| |
可以看到 GPU 的使用率一直是 100%,但是进度条却没有什么变化,感觉是哪里有性能问题了。所以基本上要放弃这个组合了,除非找到性能问题的原因,否则这个组合是无法正常使用的。起码在我以上的配置中。
最后,在等待了 34 分钟后,它终于给了我一个 77 行的 CLAUDE.md 文件。接着我发出了第二个命令“”,然后又在等了两个多小时候,任务超时了。
| |
以上的实验在我的本地 MacBook Pro M1 Max 64GB 内存的机器上进行的,使用了 Ollama 来运行 Qwen3 Coder 30B 模型,并使用 Claude Code 来分析和生成 CLAUDE.md 文件。虽然安装和配置过程很顺利,但在运行过程中遇到了性能问题,导致进度非常缓慢,最终任务超时了。结论是:本地运行 Qwen3 Coder 30B 模型与 Claude Code 的组合在我的配置下无法正常使用,除非找到性能问题的原因,否则这个组合起码在我的环境中是无法正常使用的。
用 LM Studio 在本地运行 Qwen 模型
在网上看到一篇文章介绍了这个组合:LM Studio 运行 Qwen 模型,使用 LiteLLM Proxy 来提供 API 接口给 Claude Code 来调用。这个组合的安装和配置过程也很顺利。
参考文章:Run Claude Code Locally on Apple Silicon Using LM Studio and LiteLLM (Zero Cost)
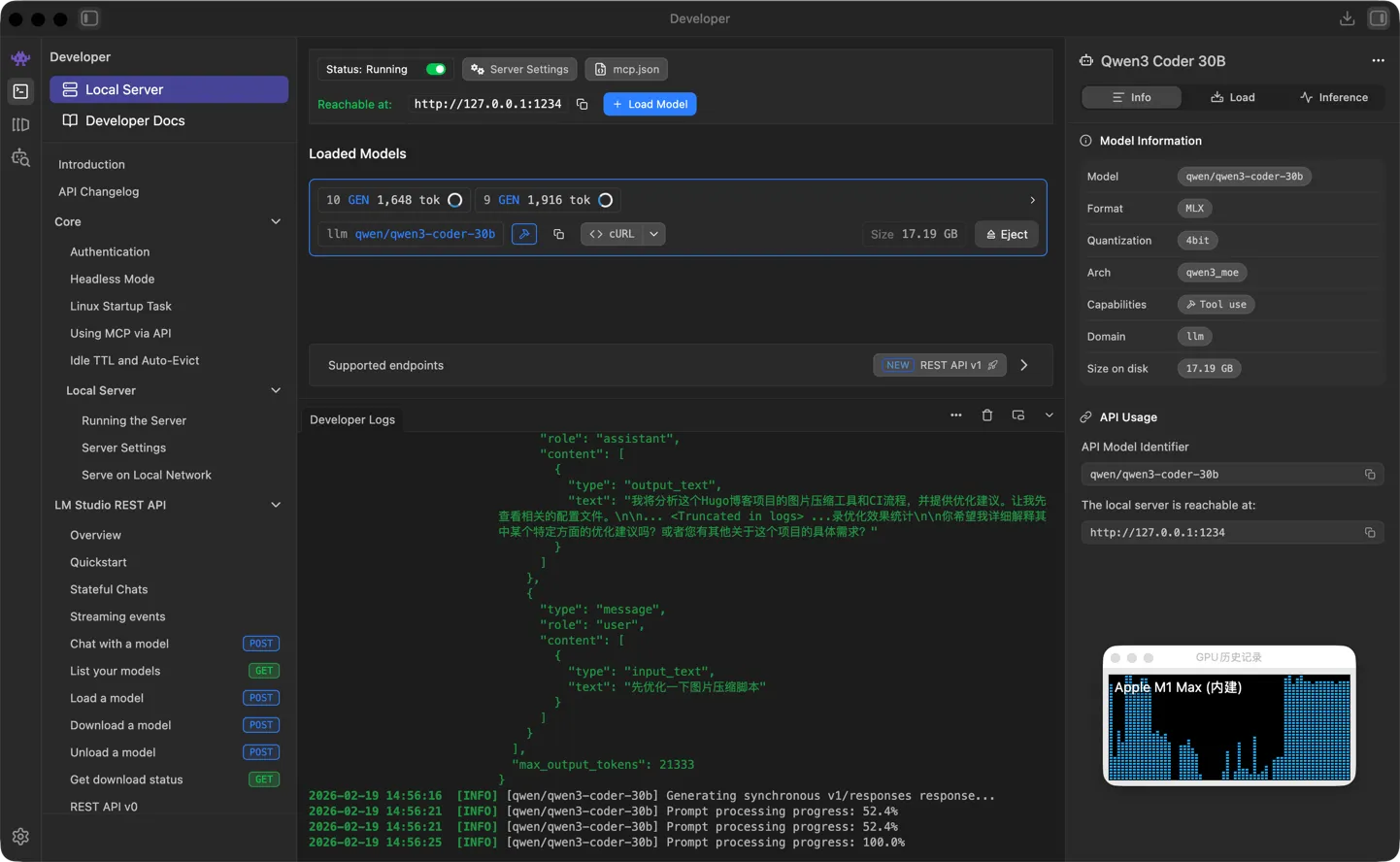
LiteLLM 使用下面的配置文件来启动:
| |
进入到目标的代码仓库中,使用下面的命令来启动 Claude Code:
| |
给了它相同的命令:
| |
从以上会话中,我在 Claude Code 中提出了相同的问题:“对这个项目的图片压缩工具和ci给出优化建议 ”,它在一分钟内给出了让我稍微惊喜的回答,接着我继续发出指令“ 先优化一下图片压缩脚本”。然后我的电脑的 GPU 就被占满了,经过了 8 分钟以后,它完成了任务。这个等待时间其实就已经证明,这个组合起码在我的这个环境中也是不可用的了。由于我不知道它改了什么,最后我问它“给出所有修改文件的diff,如果你已经修改了这些文件 ”,然后它就招不住,直接答非所问了。
使用网络版本的 Qwen 模型
最后,我也尝试了调用网络版的千问大模型。过程和方法很简单,直接访问 https://www.qianwen.com/ 然后问它:“claude code 是否可以调用你, 怎么配置?”,按照它的提示先获取好 API Key,然后就可以无痛使用了。当然,你需要提前做一些准备工作。
首先,需要用 claude logout 退出 Claude Code ,然后就可以在你的目标代码库中,使用相关的环境变量来启动 Claude Code:
| |
官方文档的集成参考命令:
| |
测试结果是完全可用的,相应速度和质量都非常不错。简单的运行了 /init 命令,它可以在 1 分 3 秒的时间给我写了一个 103 行的 CLAUDE.md 文件,内容非常全面,涵盖了代码库的概览、架构细节、开发命令、技术细节和服务依赖等方面的信息。接着我又问了它代码库中有多少文件,它给了我正确的答案 225 个文件。最后我又问了它有多少个微服务,它也正确的回答了 4 个微服务。这些结果都表明,这个组合在我的这个环境中是完全可用的,并且性能和质量都非常不错的。
Qwen 对于新用户有一个新人免费额度: 可使用各主流模型100万Token(输入+输出), 开通后90-180天内, 只对首次开通阿里云百炼平台的用户自动发放。
总结
其实我很想使用本地运行的 Qwen 模型来搭配 Claude Code 来使用的,但目前来看,不论是用 Ollma ,还是 LM Studio 与之组合,在我的这个环境中是无法正常使用的了,除非找到性能问题的原因,否则这个组合起码在我的这个环境中是无法正常使用的了。最后我还是选择了使用网络上的 API 来调用 Qwen 模型,这个组合在我的这个环境中是完全可用的,并且性能和质量都非常不错的了。由于我平时主要用的是 Codex + VS Code 的组合,后续我或许或做一个对比测试。