
最近,我一直在利用业余时间学习和试验 AWS 的数据服务,发现它们非常引人入胜。
在本文中,我们将探讨我是如何利用 AWS 服务(如 Data Catalog、DataBrew 和 DynamoDB)构建一个实时无服务器数据管道的,以及如何借助 Terraform 将其无缝部署到 AWS。
无论您是数据工程领域的新手还是经验丰富的专家,本指南都将为您提供帮助!
前提条件
为什么选择 Terraform
- 开源
- 庞大的开发者社区
- 不可变基础设施 (Immutable Infrastructure)
- IaC (Infrastructure as Code)
- 云无关性 (Cloud agnostic)
- 旨在提升我对新技术的了解
项目结构
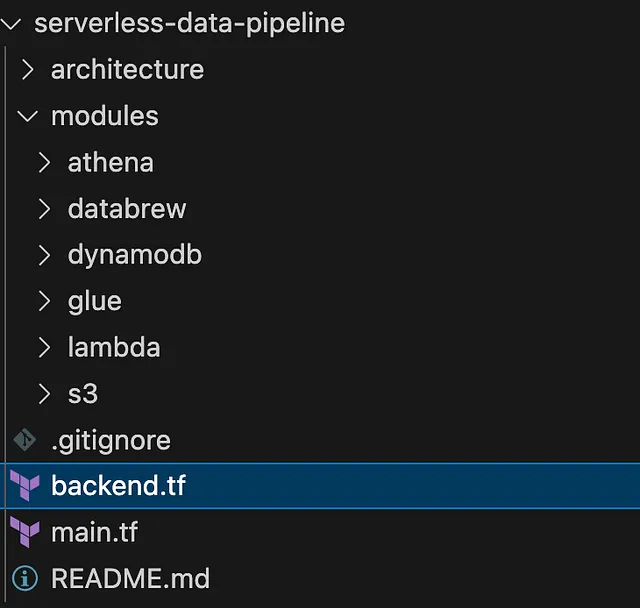
概述
我即不是数据工程师,也没有在构建数据管道项目中;但是,我最近接触了一些数据服务。结合我对 AWS 的普遍了解,我决定亲手探索一些新服务。
本文源于我将构建数据管道作为一个有趣的项目来实践的经验,我发现整个过程非常有趣且富有成效。
使用到的关键服务
1. Amazon S3
- 作为数据存储层。
- 存储了项目中使用的 JSON 文件
2. Amazon DynamoDB
- 作为数据库层。
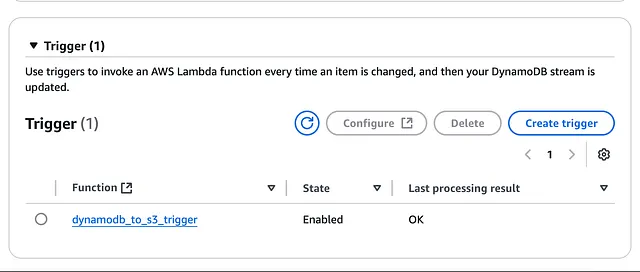
- 使用 DynamoDB 流 (DynamoDB streams) 和 AWS Lambda 将 JSON 数据从 DynamoDB 导出到 S3
3. AWS Glue
- 负责数据提取、转换和加载 (ETL - Extraction, Transformation, and Loading)。
- 使用 Glue Data Catalog 管理数据集的元数据 (metadata)。
- 它还支持使用爬网程序 (crawler) 进行爬网,该程序自动发现架构 (schema) 并创建表;然而,在这个项目中,我们手动定义了架构,因此不需要此功能。
4. Amazon DataBrew
- 用于转换 S3 中存储的数据,方法是删除重复条目。
- 一旦项目放置在 S3 存储桶的路径
/data中,它就会作为触发作业(来自 Lambda)运行。 - 指向 Glue Data Catalog 作为输入数据集。
5. Amazon Athena
- 使用标准 SQL 查询存储在 Glue Catalog 中的转换数据。
- 完全无服务器,并与 Glue Data Catalog 集成。
最终架构
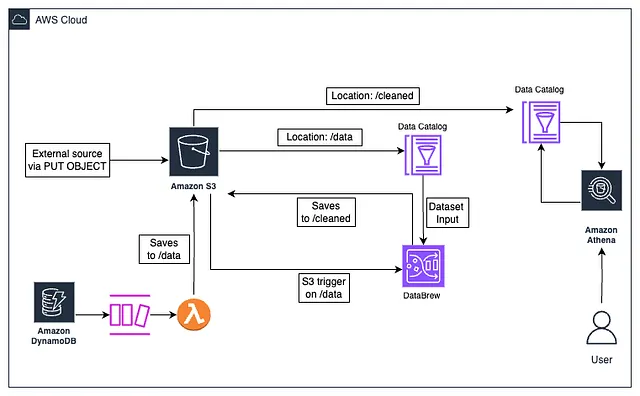
架构解释
第一流程
- 一个 .json 文件被添加到 S3 上的路径
/data - 第一个 Glue 数据目录表 (Glue Catalog Table) 从 S3 的
/data路径读取数据 - 上传到
/data会触发一个 Lambda 函数,该函数启动 DataBrew 转换作业,通过移除email列中的任何重复行来清理第一个 Glue 数据目录表(输入数据集)中的数据 - DataBrew 作业将转换后的数据输出到 S3 中的新路径
/cleaned下,覆盖该路径中的其他项目以避免输出路径中出现重复 - 第二个 Glue 数据目录表从 S3 的
/cleaned路径读取数据 - Athena 工作组 (workgroup) 从第二个 Glue 数据目录表读取数据并对其运行查询。这反过来又将查询结果存储在 S3 中的新输出位置
/athena-results/
第二流程
- 一条数据被添加到 DynamoDB。
- 随着新数据的增加,DynamoDB 流 (stream) 被触发
- 连接到 DynamoDB 流的 Lambda 函数(用 Python 编写)被调用,它将新项目转换为 .json 文件
- 执行第一个流程中的所有步骤
总而言之,实时数据处理的目标是通过 DynamoDB Streams 和 S3 存储桶通知 (S3 Bucket Notification) 与 Lambda 的集成来实现的。
代码定义
main.tf
提供商 (Provider):第一步通常是定义提供商。这里我们将云提供商定义为 aws。
此外,我们还包含了将在项目中使用的各种模块 (module),并传入所有必需的变量。
| |
| |
backend.tf
首先,创建 S3 存储桶用于远程存储 Terraform 状态文件 (state file),这有助于促进协作。
创建后,将以下内容添加到 backend.tf 文件中:
| |
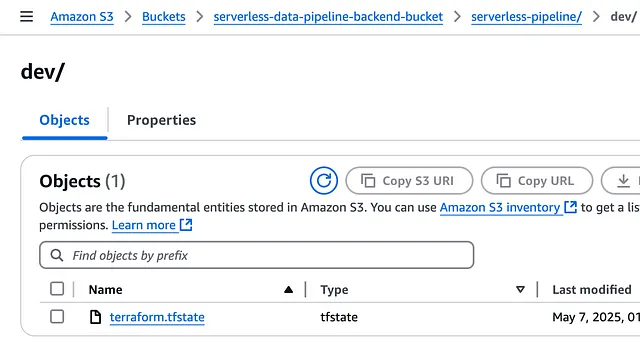
一旦我们运行 terraform init 和 terraform apply 来部署项目,我们就应该看到状态存储在存储桶中,如下所示:
- module/main.tf : 每个服务的基础设施和配置都放置在各自的
main.tf文件中 - module/output.tf : 每个服务的输出详情 (output detail) 都放置在各自的
output.tf文件中 - module/variable.tf : 每个服务期望的输入变量 (input variables) 都放置在各自的
variable.tf文件中
部署应用程序
现在我们已准备好部署应用程序。运行以下命令进行部署。
Terraform init:这会初始化项目,拉取部署所需的所有必要软件包。
| |
Terraform plan:这会显示提议的更改,在部署前发现任何意外更改时非常有用。
| |
Terraform apply:这会将项目部署到 AWS。
| |
测试应用程序
S3 存储桶 (S3 bucket) 最初加载了一个 sample.json 文件,其内容如下:
| |
注: 如您所见,我们有一个重复的电子邮件地址 *[email protected]*,理想的结果是移除这个重复条目。
这个文件是在使用 Terraform 创建存储桶后立即上传的,因此它不会触发 DataBrew 作业,因为该触发器设置是在项目的后期才进行的。
为了测试实时功能 (Real-time feature) 和项目的完整流程,我们可以向 S3 上传新对象,或向 DynamoDB 添加新条目。我们将向 DynamoDB 添加一个新条目来测试完整流程:
通过 AWS 控制台 (console) 进入 DynamoDB,并添加一条新数据:
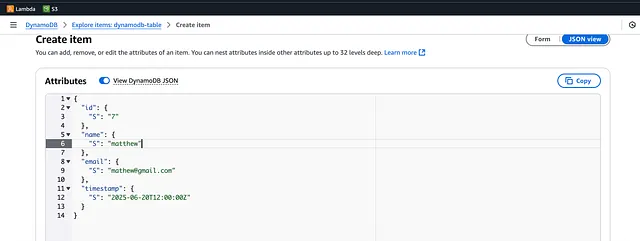
添加此条目将触发 DynamoDB 流 (stream),它会使用关联的 Lambda 函数 (lambda function) 将新对象插入 S3。
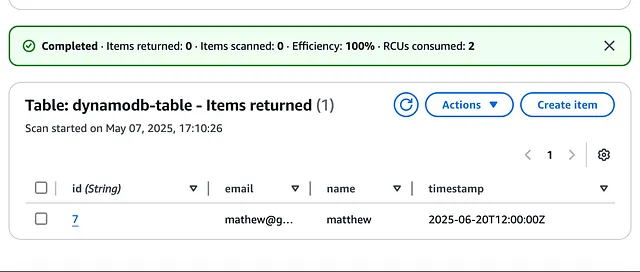
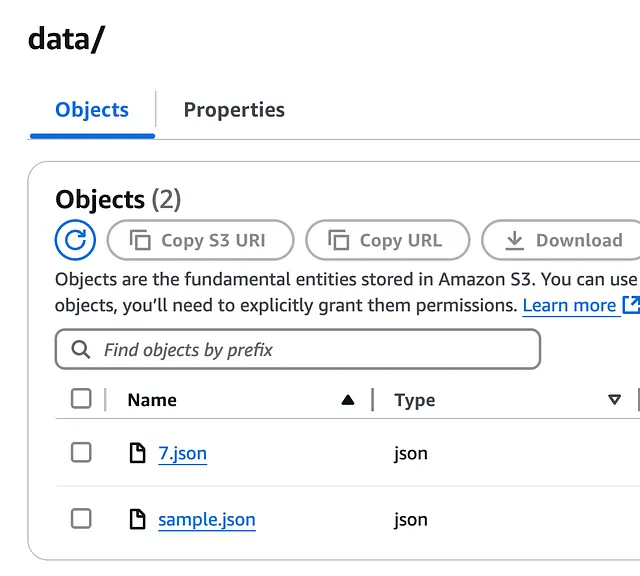
前往 S3,我们看到新条目 7.json 已添加:
接下来,前往数据目录 (Data Catalog),我们看到数据库 (Databases) 和表 (Tables)。
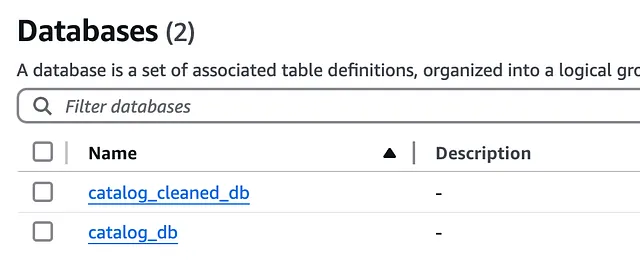
数据目录数据库
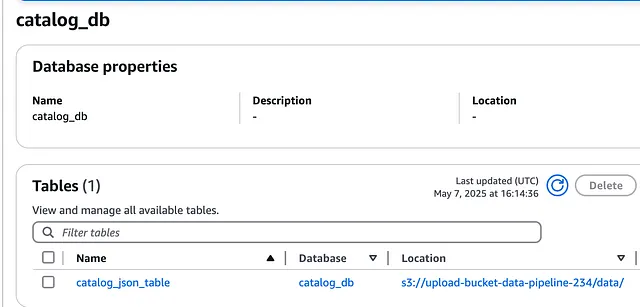
数据目录表
前往 DataBrew,我们看到该项目。
一旦 Lambda 函数被添加到 /data 路径的新内容触发,它就会启动 DataBrew 转换作业 (transformation job):
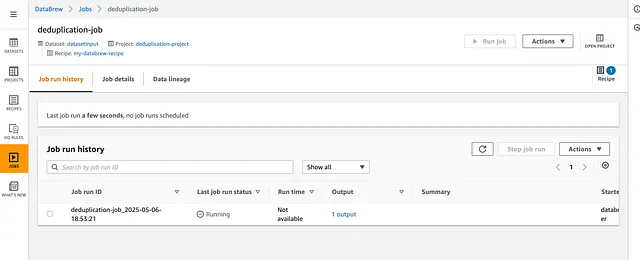
完成后,它看起来像这样:
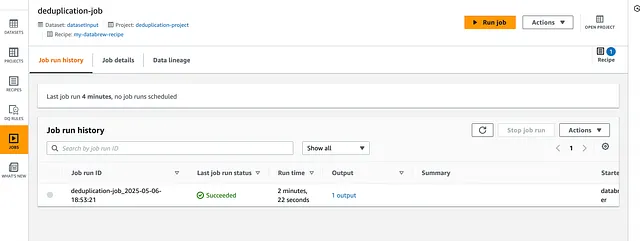
已完成的 DataBrew 作业
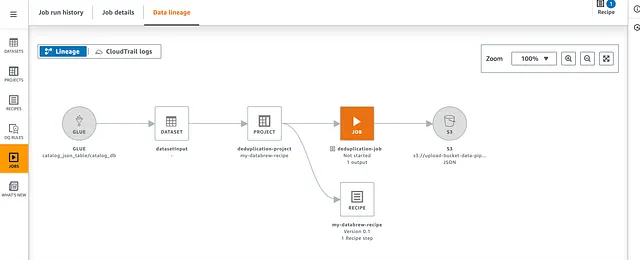
DataBrew 数据血缘 (Data lineage) 允许我们查看使用 DataBrew 的流程的图形化表示。
空闲作业:
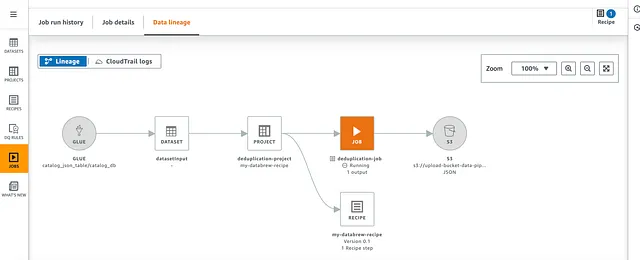
运行中作业:
最后,前往 Athena,并选择 my-athena-workgroup 工作组 (workgroup) 来运行查询。
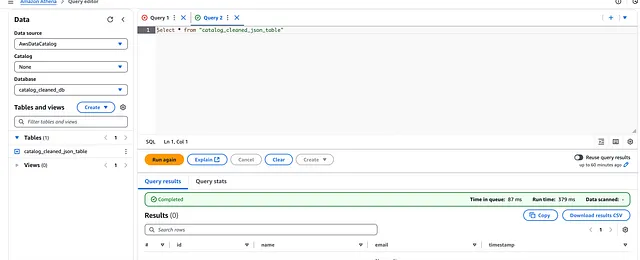
在 DataBrew 作业运行之前,如果我们使用 Athena 运行查询,将不会有任何结果,因为 /cleaned 路径中还没有任何项目:
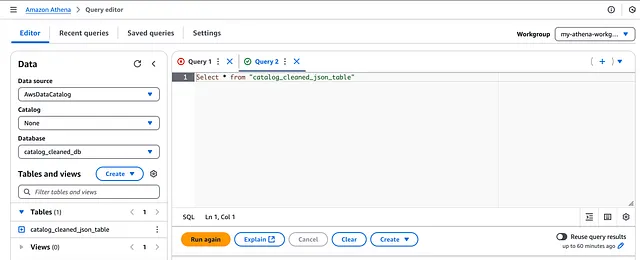
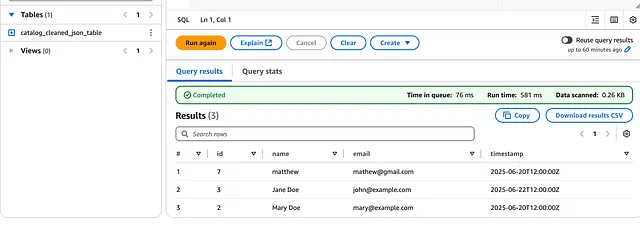
然而,在 DataBrew 作业成功运行后,我们点击 Run again 按钮以在 Athena 中重新运行查询:
结果如下:
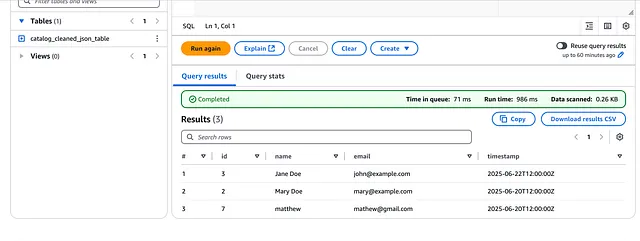
如果你仔细观察,会发现它移除了在项目创建时上传到 S3 的 sample.json 文件中发现的邮箱为 [email protected] 的重复条目。
它还添加了邮箱为 [email protected] 的新的 DynamoDB 条目。
这意味着我们的管道按预期工作!!
通过 DynamoDB 添加重复条目
让我们通过向 DynamoDB 添加一个新条目来进一步测试,但这次它的邮箱将与我们现有的记录匹配。
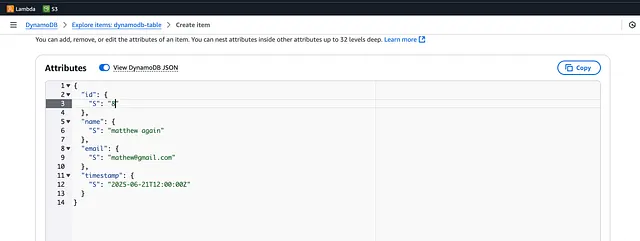
我们添加了一个邮箱为 [email protected] 的新冲突条目
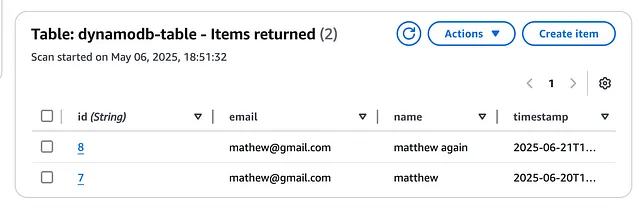
这将触发一个新的 DataBrew 作业 (Job):
一旦成功了,我们会看到下图:
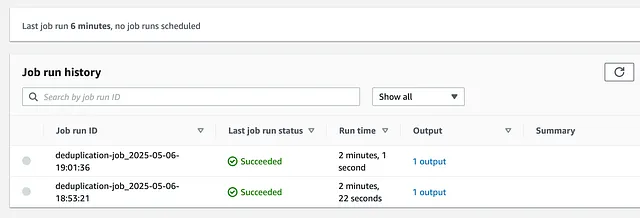
接下来,前往 Athena 再次运行查询,这次它不再包含重复记录了!
结论
我创建这个项目和文章是为了提高我在 Terraform 方面的技能,并亲自动手实践数据工程领域,同时磨练我的 Python 技能。
你可以在 这里 找到完整的源代码。
我希望这篇文章能帮助你对在 AWS 中构建数据工程项目更有信心。我很高兴看到你将创造出什么!
全栈开发人员、技术作家和 Jamstack 爱好者。热爱终身学习。