
用跟踪的方式调试计算机程序的调用堆栈的实践其实由来已久,这种方法可能仅次于用 print 输出各种信息。在云原生的时代里,我们还会遭遇工具过剩的情况,工具之间的相生相克加剧了实施分布式追踪的难度。
总的来说有三个基础难点:
- 生成追踪数据难。对已有应用系统的代码库进行埋点处理的挑战巨大,你的应用程序系统的模式可能也不符合埋点的模式需求。
- 采集存储追踪数据难。捕获和管理大量追踪数据包,即照顾到查询和使用的需求,又要设定成本合理的数据存储策略,处理数据收集能力的扩缩容。
- 从数据中获益难。如何理解和使用数据产生可执行行动,如何用它优化微服务的遥测,怎么将它的利益扩展到各个相关团队。
分布式追踪系统的实施结果是落地一条能深度洞察目标系统的工具。让人们能轻松的理解局部和整体的状态,特别是在请求堆栈中的任何局部服务出现故障时,可以最快速的定位故障根源。

上图是用追踪数据生成的服务地图。
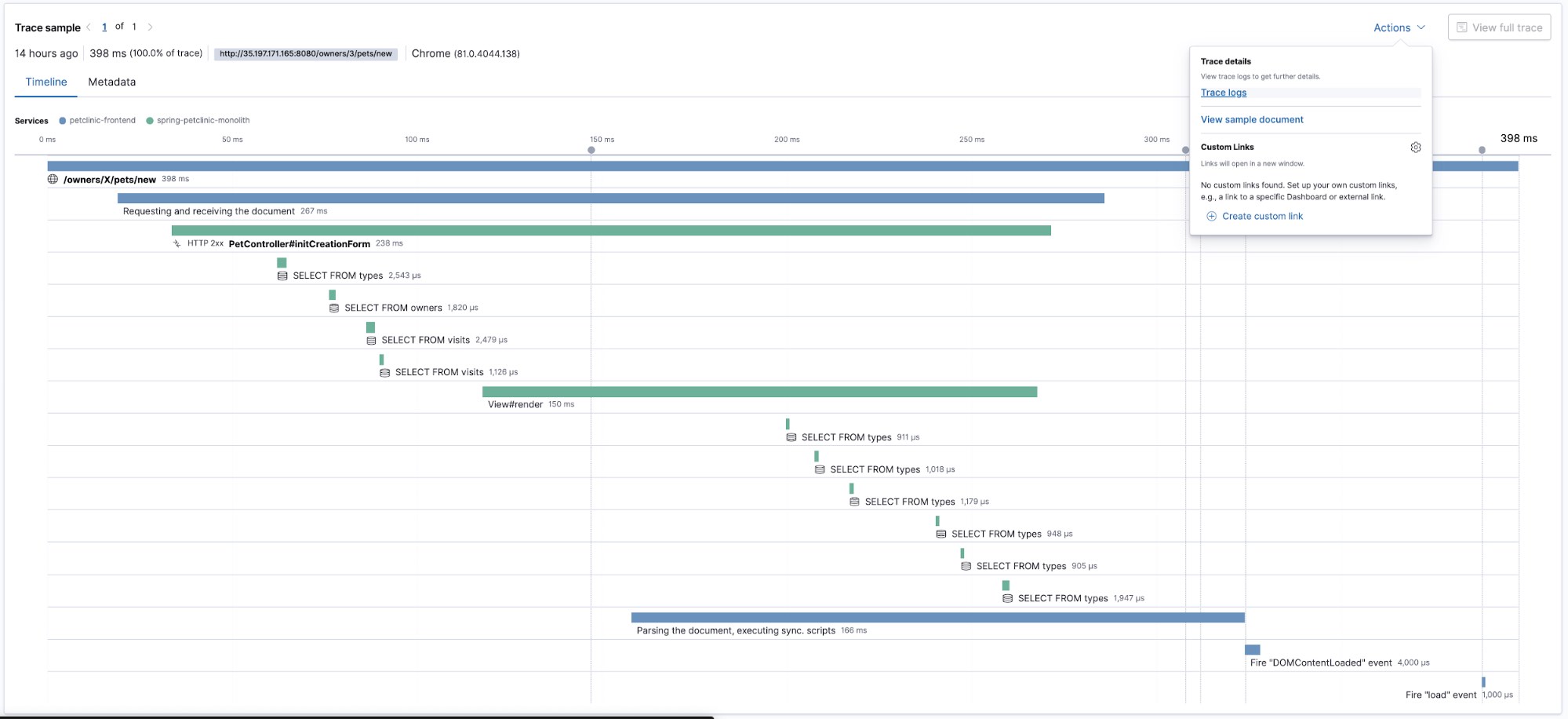
上图是一次用户请求的全部细节,还可以一键式的跳转到相应的日志或者指标。
以上三个难点覆盖了部署实施分布式追踪系统的核心领域。
- 埋点 OpenTelemetry是目前受到广泛支持的埋点框架,对棕地应用和绿地应用进行埋点处理的挑战是不同的,需要遵循不同的额最佳实践。
- 部署 在理解了目标追踪应用系统的运行时状态后,最好使用一种弹性的方式收集和存储追踪数据。满足分析数据量需求的同时平衡存储成本。
- 收益 将其与日志和指标工具关联起来,定义和监控重要有意义的监控点,用于优化系统性能基线,并最小化 MTTR。
在云计算、Kubernetes、容器化大行其道的今天,分布式追踪的实施是不是正处在进退维谷的尴尬境地呢?其实并非如此,特别是监控运维挑战越高的应用,其实越需要需要使用分布式追踪 APM 工具。分布式追踪对云原生的容器化微服务应用尤为适用。APM 对单纯使用日志和指标的场景具有极大的补充和提高作用,而且它是可观测性策略的关键组成部分。
总的来说分布式追踪工具可以通过追踪的方式展现请求在系统中的流动状态。流行的开源埋点框架使之与应用的编程语言、运行时环境无关,可以适配与所有类型的应用和服务。有些 APM 工具可以支持运行时埋点(或称为运行框架埋点),在不改变代码的情况下采集追踪数据。APM 的实施虽然有一定难度,但是当开始实施埋点处理,收集追踪数据以后,相关的价值和收益也就会慢慢显现出来了。
参考: